Earthquake - Navigating Through the Tool - User Instructions
This section describes the use of each tab in the user interface and aims to guide the user through running the model from start to finish. Each tab has its own section and it is suggested you move through each of these in sequence.
0. Introduction
What does it do?
This Introduction tab is included purely as a reference for users and does not affect the app in any other way. The tab gives a brief overview of the tool similar to these help pages.
Risk Explorer Introduction Tab
1. Hazard
What does it do?
The hazard tab is where you specify the types of events you wish to model and the data to be used to do this. The perils and data sources you select here will feed into the simulation approach used on later tabs. In this tab you will load an appropriate hazard data set based on the location of your exposure and the peril you wish to model.
User Instructions
The hazard tab is where you specify the nature of the events you are interested in modelling as well as what source you will be using to model these. There are a few input boxes to complete before loading the data. The selectable values in each box will differ depending on the selections you make in the boxes above. Make sure you enter these in the order they are listed on the page. The subsequent steps will guide you through appropriate selections for each of the dropdown boxes pictured in the screenshot below.
Step 1.1: Select the peril you want to model: A peril is a specific type of event. Select earthquake (currently only available in Risk Explorer for Karachi in Pakistan).
Step 1.2: Select the hazard data type used to model your chosen peril: For earthquake, stochastic event sets is available. This is simulated data derived from stochastic event sets put together by catastrophe modelling experts. Event sets are presently only available for certain regions and perils.
Note that the content of the later analysis tabs will differ based on your selection here. This is because the approach used to simulate losses differs substantially between each data type.
Step 1.3: Select the specific region you are interested in modelling: Note that the region groupings available differ depending on the peril and hazard data type you select. This is due to different perils having their roots in different natural phenomena and relying on data sources that may approach these groupings slightly differently.
For stochastic datasets, the following options are available to select:
Earthquake Pakistan (Karachi) – Aon Impact Forecasting
Step 1.4: Select which meteorological agency to use as the data source: This is a concern where you are using an IBTrACS historical dataset, for stochastic hazard data, simply select N/A here. For each basin, IBTrACS data contains wind/track measurements from several agencies. Most of these relate to national meteorological agencies e.g., TOKYO is the Japanese agency and CMA is the Chinese agency. Measurements can differ between agencies, so this is an important step. For some basins, the prompt below the input box may recommend that you choose a particular agency. For more information on the different meteorological agencies, please see the glossary_reference-label.
Step 1.5: Load the data: Once you are happy with your selections in the drop-downs above, select the “Load Hazard Data” button at the bottom of the page. The application should display a notification when the hazard data has loaded and confirm your selection on the page.
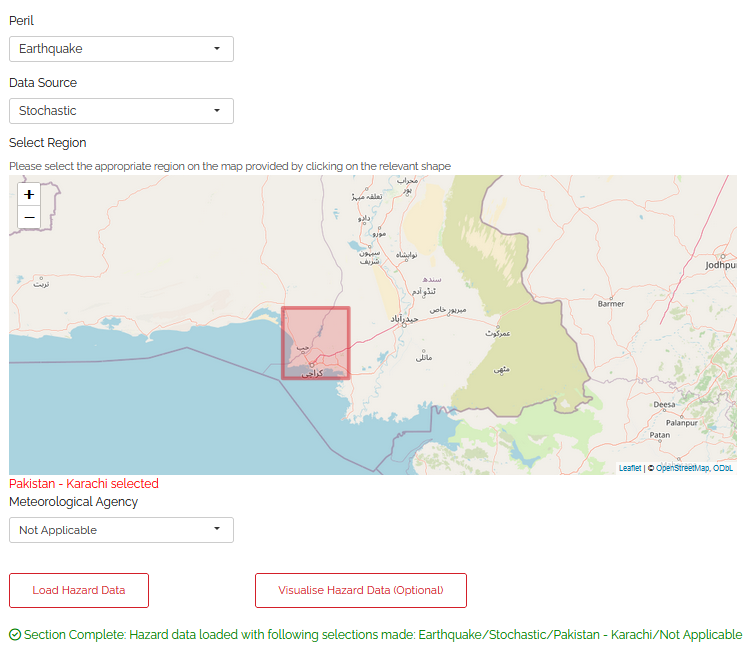
2. Exposure
What does it do?
The exposure tab is where you should specify the asset or area you want to model. The exposure(s) can be defined as a specific location or an area that is assumed to include multiple assets. You should also specify the asset(s)’s value which will be used in the simulation section to calculate potential losses. Exposure can be defined by either a single latitude-longitude point or a circle-shaped area around a specified point. The reason exposure is entered in this way is that the Risk Explorer aims to keep each section as simple as possible. The model also aims to introduce users to the basics of parametric insurance where covers are generally defined in terms of co-ordinates on a map rather than underlying physical assets (See What is parametric insurance? for more info on the topic).
Select a single location where there is one asset in particular you want to model (e.g., a particular factory building or apartment block). Where you wish to cover a number of assets (e.g., a town, island or even a whole country), it would make more sense to use an area. You can experiment with the size of your circle until the required assets are covered. The location or area you enter in this tab will ultimately feed through to your simulations when the modelling is run.
User Instructions
Step 1: Enter the latitude/longitude co-ordinates of the location or centre of the area you are interested in covering: There are three different ways you can enter these. The method you choose will depend on the information you have about your location/area.
If you know the latitude and longitude of the location/centre of the area then you can enter this directly: Enter “Yes” to the first question in Step 1. You will then see two input boxes below the map where you can enter your latitudes and longitudes. Once you have entered both of these, the location you have selected will display on the map. Before moving to the next step, ensure the location selected on the map is what you were expecting.
If you know the address of the location/centre of the area then you can search for it directly: Enter “No” to the first question in Step 1. Click the magnifying glass icon displayed in the top-left of the map screen. A text input box will appear where you can search for your address. The address search uses OpenStreetMap with addresses generally displayed in the native language of the country they are located in. Once you have entered your address and selected one of the options from the drop-down, the location you have selected will display on the map. There is a chance your address may not be listed. If this is the case, you may need to enter your location using the third method outlined below.
If you know neither the address or the latitude and longitude: Enter “No” to the first question in Step 1. You should then use the map’s zoom and drag functionality to find the approximate area you think your exposure is located in. Click on the map and the location you have selected will display. Keep clicking on the map and zooming as required until you have selected the location you wish to select.
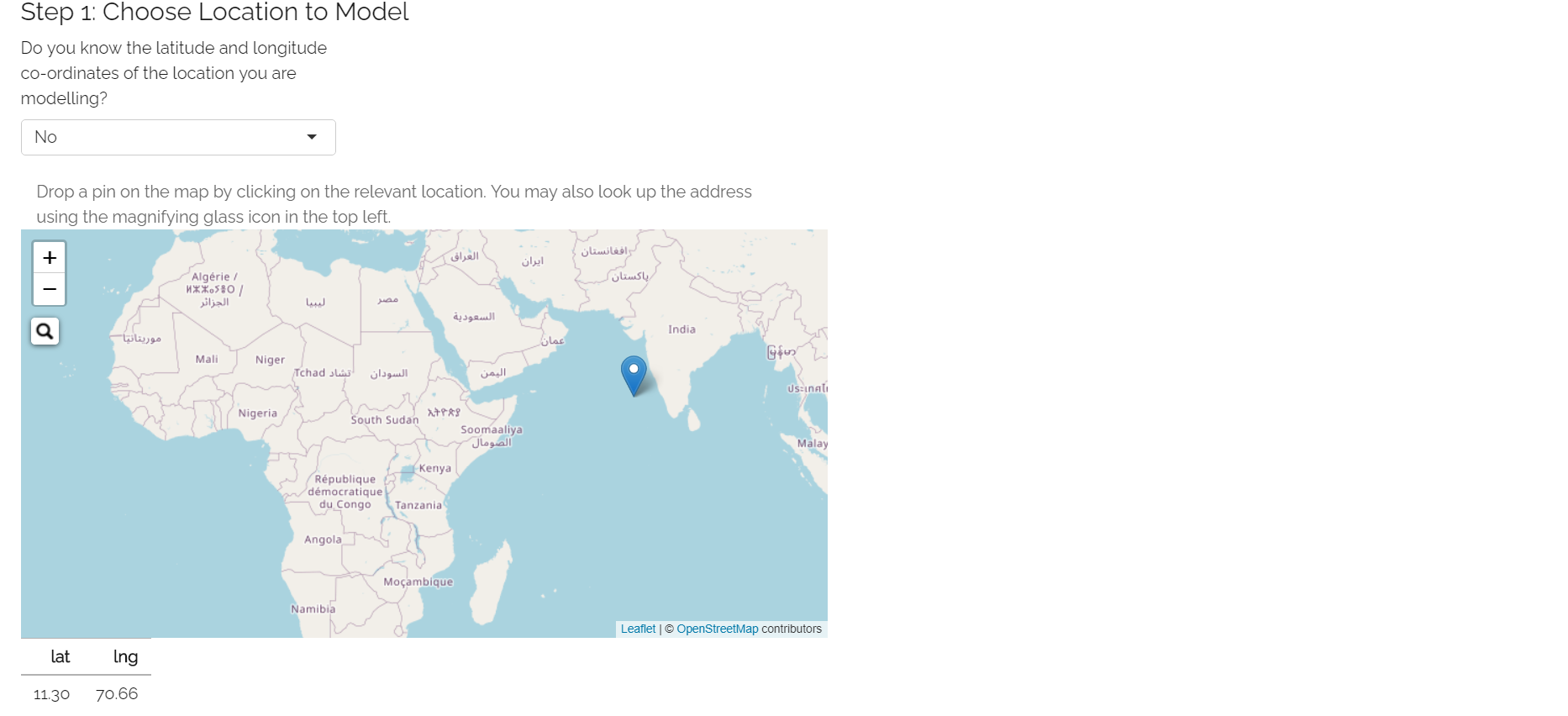
Exposure Step 1
Step 2: Specify the area you want your insurance policy to cover.
If you are looking to model a single location, you will be able to just enter zero here. If you are looking at modelling an area rather than a single location, you will specify the radius that you believe is representative of the area. This will define the total area in which the insurance cover will respond. You can also easily experiment with different radii using the map.
It is suggested that you choose the smallest possible radius that captures the area you wish to cover. The reason for this is that any additional area specified is likely to increase the chance of you sustaining losses when the area you are interested in covering isn’t actually impacted by an event. Also if you were looking at purchasing an insurance cover, a greater chance of payouts would mean that the insurance cover would ultimately be more expensive to buy. Note that the tool currently only allows you to specify an area of up to 200km radius. This is to prevent calculation issues.
Step 3: Enter your asset value and currency Enter the total value of the assets you are covering and select an appropriate currency from the list provided. Note that you must enter an asset value greater than zero here.The asset value can be thought of as the total cost of re-building your assets and could also include any further economic loss from a catastrophe (e.g., lost revenue from business interruption). If you were modelling parametric insurance through the tool, you could also think of the asset value as your maximum payout under the cover. Screenshot here
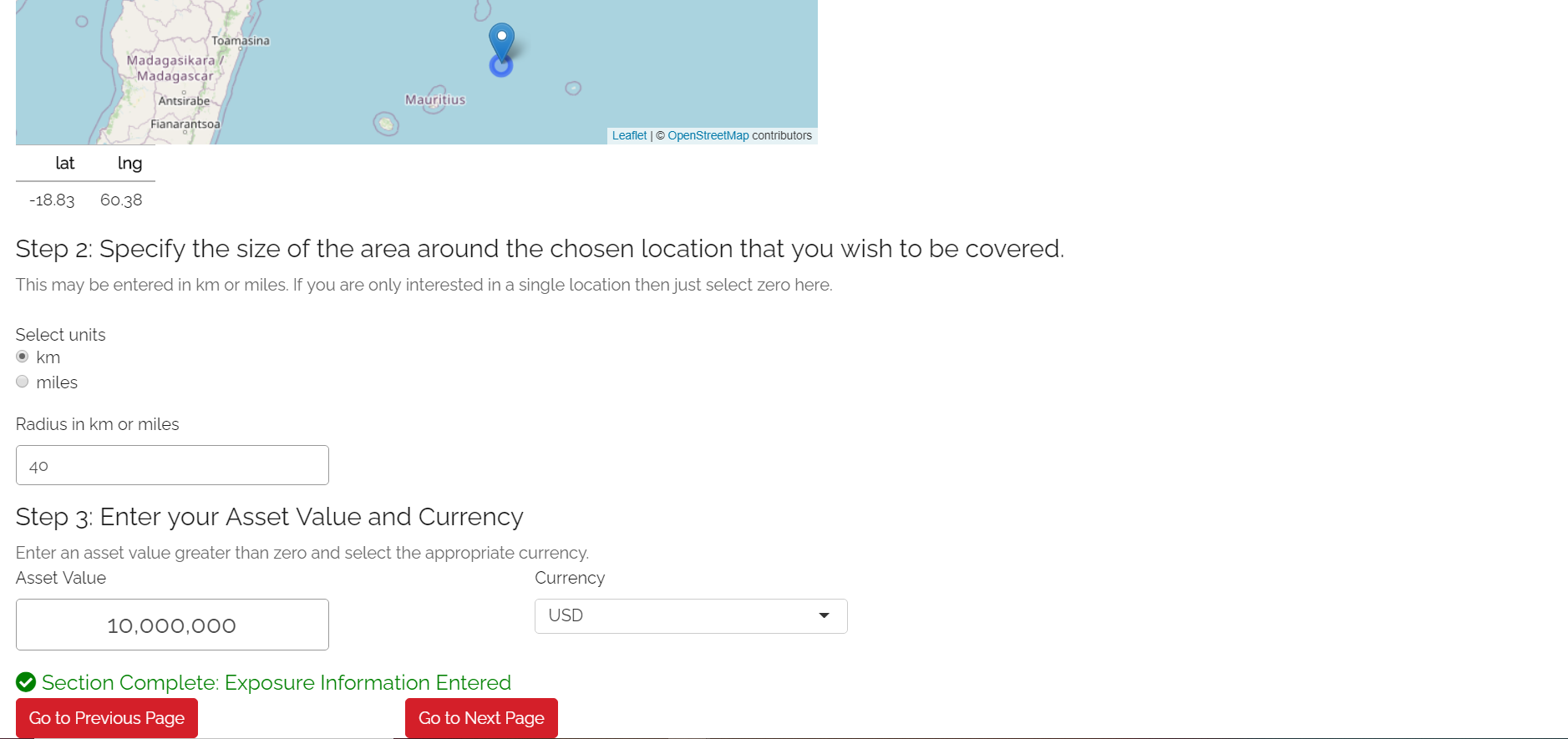
Exposure Step 2 and 3
Appendix: Step 2: Why can only circles be entered here? At present, circles are the only exposure shapes that can be specified within the tool. There are a few benefits to using circles rather than squares/rectangles to mark out the exposure area:
Tropical cyclones (the original peril in this tool) are circular. Using circles means the exposure area and simulation methodology tie in more closely with the hazard itself. This should also typically lead to less losses in cases where cyclones skirt the edge of an exposure area. This helps increase the likelihood of losses being generated in response to events are actually causing actual losses.
Straightforward to specify. Only one location and one radius parameter need to be entered.
It is worth bearing in mind that for exposure areas that are long and thin (e.g., a long line of locations along a coastline), the circle approach may not be optimal. While this is recognised as a limitation of the tool, only circles can be specified here to ensure the tool retains its simplicity.
3. Vulnerability
What does it do?
The vulnerability tab defines how physical events translate into damage/financial loss. You will define this as a relationship between your intensity measure (e.g., wind speed) and a damage percentage. This is done by specifying the main input on this tab which is the vulnerability curve. This curve will assign a given damage percentage to each value of the intensity measure. In the Risk Explorer, damage is measured as a percentage of the total asset value. It is assumed this directly corresponds to the financial cost of repairing any damage. The shape of your curve will vary based on what you know about your exposure and what you’re using the model for.
Note that although there is currently no explicit tab in the model for structuring insurance, the vulnerability and the insurance structure are essentially the same thing for parametric insurance covers. The financial loss is solely defined by your trigger measure and payouts which are essentially equivalent to the intensity measure and damage percentages in the vulnerability tab. As such, you can also allow for simple parametric structures through this tab, however the terminology used throughout would differ slightly (e.g., rather than asset value, you would be talking about maximum insured). See the What is parametric insurance? for more detail on parametric insurance.
User Instructions
Step 1: Specify the intensity measure. The intensity measure is a hazard intensity parameter that should be closely related to the likely damage caused by an event. For example, wind speed or pressure would be suitable measures for a storm, as they closely relate to the amount of damage likely to be caused. Recordings of the intensity measure within your defined exposure area will determine the damage sustained in an event. Guidance should appear at this step to advise you which intensity measures are likely to be appropriate based on your selections on the Hazard tab. Once you have selected your intensity measure, you then choose which units to specify it in - though current data only allows percent of gravity (g%).
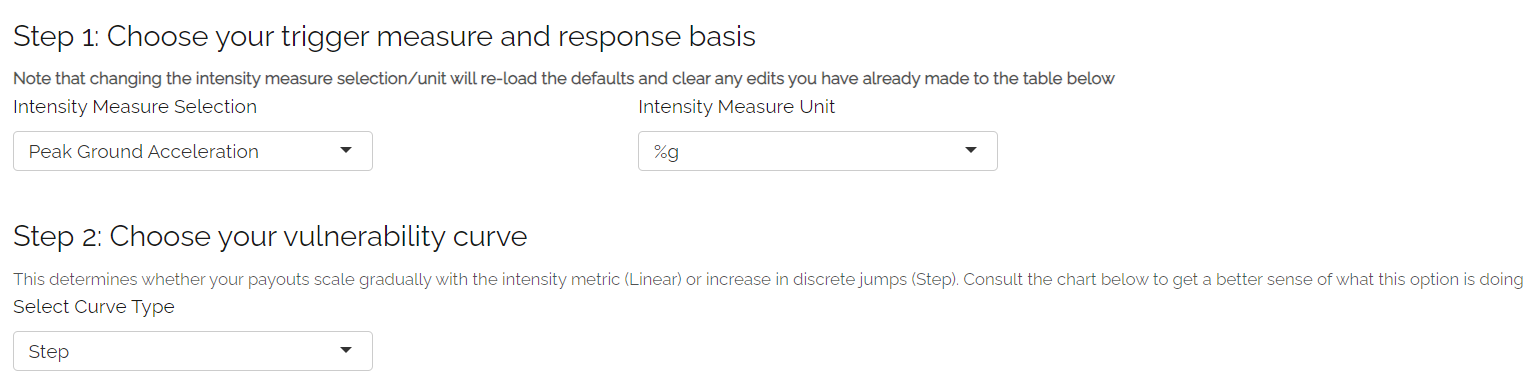
Vulnerability Tab: Steps 1 and 2
Step 2: Choose your vulnerability curve type. The curve type you enter determines how the damage percentages you enter change as the intensity measure increases/decreases. You can choose from a stepped or linear vulnerability curve. It is worth trying both options and consulting the graph below to see how this works in practice.
Step: This curve replicates how most parametric covers work. The damage generated increases in “steps” corresponding to the highest specified intensity measure exceeded. For example, with the default values in the grid below (these will appear once you’ve completed the first step), it would be assumed that you would sustain damage amounting to 20% of your asset’s value if wind speeds greater than 119km/h are recorded at your chosen exposure. However, if winds exceeding 154km/h were recorded you would sustain damage amounting to 40% of your asset’s value.
Linear: This curve is closer to the approach used in catastrophe modelling, where a more detailed approach is used to specify the damage generated at each value of the intensity measure. The damage generated increases linearly for the values you enter in the grid. For example, with the default values below, it would be assumed that you would sustain damage amounting to 20% of your asset’s value if wind speeds of 119km/h are recorded and 40% of your asset’s value if winds of 154km/h were recorded. For wind speeds between these two points, it is assumed damage increases linearly with wind speed. For example, winds of 136.5km/h would lead to 30% damage whereas in the step function example, this would still be 20%.
The curve you select is likely to differ based on the aim of your modelling. If you are trying to replicate parametric insurance payouts, the stepped curve is likely the more suitable option. By contrast, if you are trying to closely model likely damage to the underlying asset, the linear curve may be a more appropriate selection. The graphs below show what each curve type looks like with default values for intensity and damage.
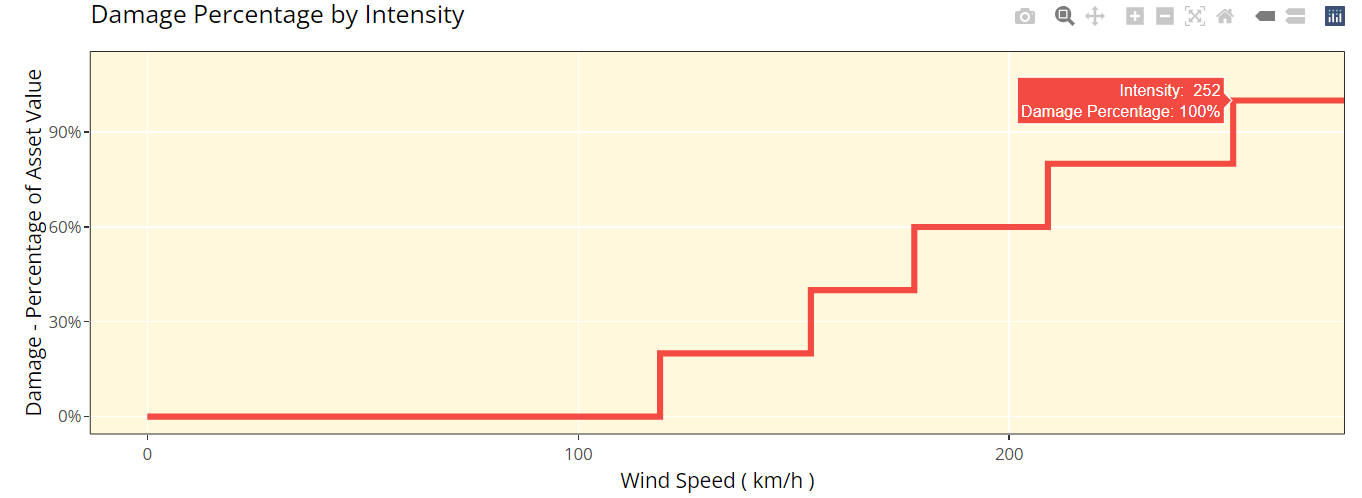
Vulnerability Tab Step 2: Stepped Curve
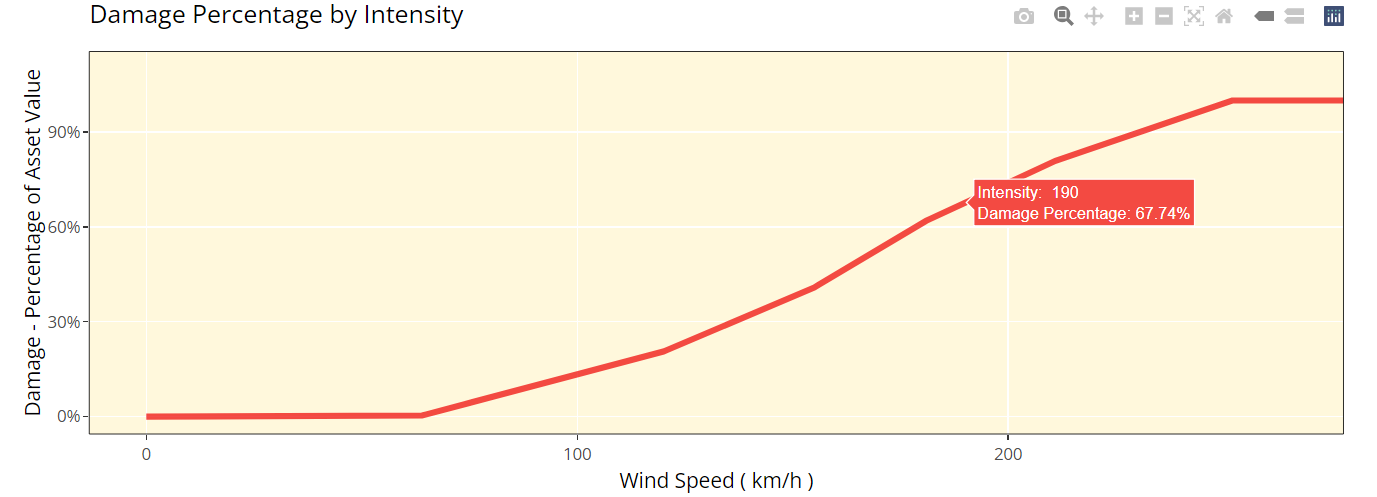
Vulnerability Tab Step 2: Linear Curve
Step 3: Enter your damage percentage at each level of intensity
Together with step 2, the values you enter here will determine the overall shape of your vulnerability curve. The columns for intensity and damage percentage highlighted in red in the table below are editable by double-clicking on the table. After making your edits, press Ctrl + Enter to save these and exit the table’s edit mode. Note that the damage percentage must be entered as a decimal so 40% of the maximum amount would be entered as 0.4.
For earthquake, the default values in the table correspond to Modified Mercalli Intensity Index (MMI) intensities from V to X. Different bandings by PGA are assumed to reflect different MMI intensities based off a standard USGS conversion.
You may want to edit the damage percentages to reflect what you know about the cost of previous events for your area of exposure. The graph at the bottom will also update based on the values you enter in the table. This should act as a visual aid to see what damage would occur for each value of the intensity measure/trigger measure.
Notes for specifying points on your vulnerability curve:
If you’ve selected pga as an intensity measure, damage percentages and intensity values should be entered in ascending order. For pressure, intensity values should be entered in descending order. This is because lower pressure correlates with more serious events.
Note that you do not need to use all six rows if you do not want to and can leave any extra rows at the bottom blank. You need to enter a minimum of one row for a stepped curve and a minimum of two rows for a linear curve.
No individual rows should have a damage percentage exceeding 100%, as an asset being more than fully destroyed in an event doesn’t make logical sense.
If you are still unsure what to enter for any of these fields, you can just use the default values given in the tool.
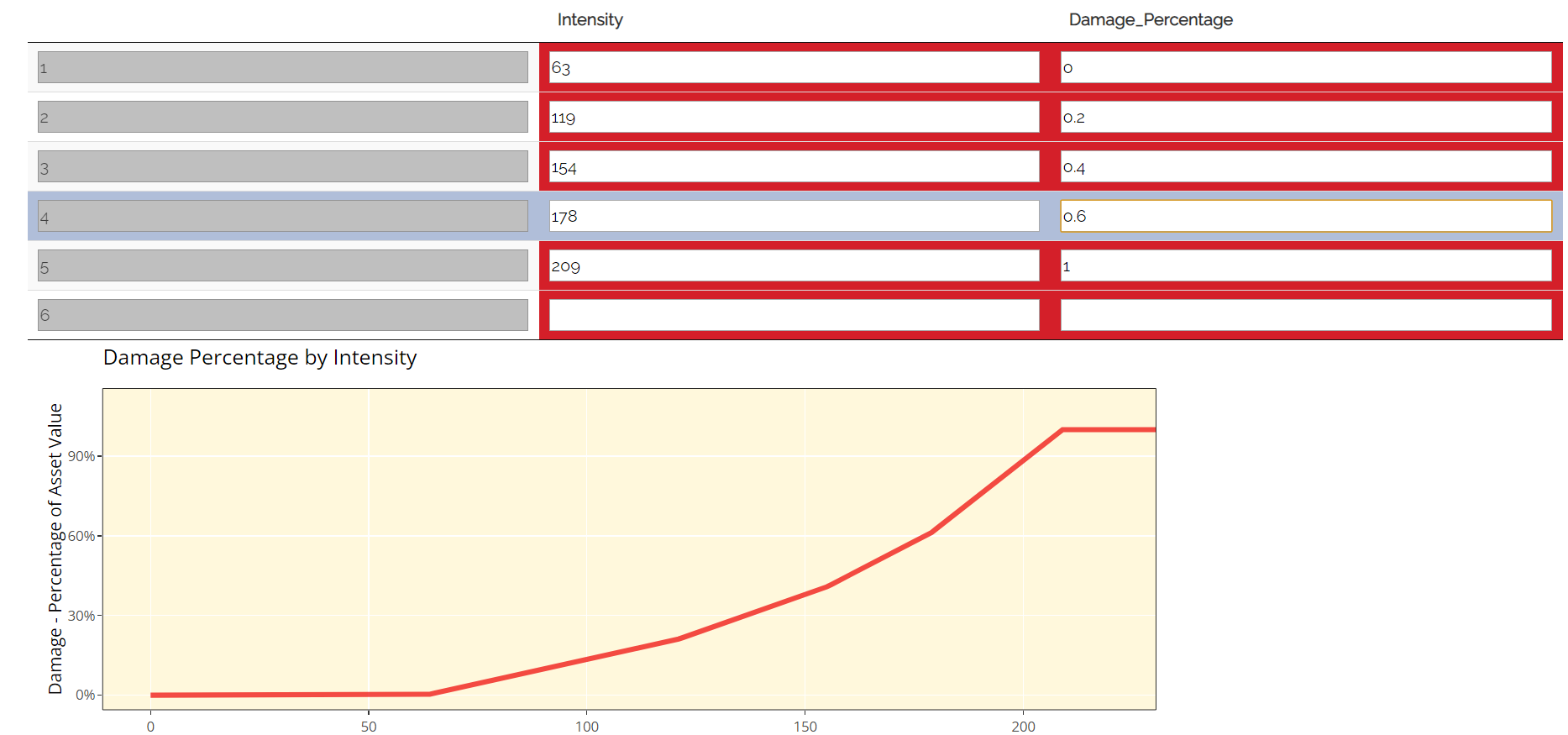
Vulnerability Tab: Step 3
4. Simulation
What does it do?
The simulation tab is where you run the simulation modelling that feeds the app’s main outputs. The simulation engine is based on a simple and transparent methodology. Note that the underlying method differs for stochastic hazard sets and historical hazard data.
For stochastic sets, the model providers have already pulled together the event set, so the simulation methodology essentially just randomises across their data and applies the vulnerability function to each event. The background calculations going on in this tab are a lot more involved than the other sections, as such a more detailed description of the simulation method can be found in the Tropical Cyclone - How does the Simulation Methodology Work? section. A brief and relatively non-technical description is given below for each type of hazard data, however you will need to look at the more detailed explanation to fully grasp the method and its applications.
Stochastic Hazard Data
Step 1: Filter the events in the stochastic dataset that are relevant to your exposure. The dataset is made up of a large number of simulated years, each with their own specific events. The first step of the calculation excludes events that are too far away to impact your exposure area. Only events that occur within your exposure area are used in the subsequent calculations.
Step 2: Randomly select years from the dataset for each simulation. The selected years from the stochastic data and their corresponding events will then be used to calculate losses in later steps. Note that as the years in the stochastic data are selected at random, it is possible that certain years may repeat for a large number of simulations.
Step 3: Identify the events in each simulation that would lead to losses. This step looks at which events in your simulations would have led to losses based on values of the specified intensity measure in the vulnerability section. These losses are then summed up across each simulation and capped at your total asset value.
Step 4: Average across losses by simulation to give an overall expected loss. Each simulation should have a total loss associated with it calculated in step 3. This step averages across all of these simulation losses to give an overall expected loss.
User Instructions
Only run simulations once the exposure, hazard and vulnerability sections are complete as indicated by the checklist. Once you are happy with your inputs, you can specify the number of simulations you wish to run before clicking “Run Simulation”. Note that in some cases, the application may flash up a warning instructing you to re-enter an input if there are issues with the selections you have made in the other sections.
The more simulations you run, the more stable/reliable your output will be, however a higher number of simulations will take longer to run. If this tool is being used in a purely educational capacity, even 500 should produce meaningful output. It is suggested you try this amount initially to ensure there are no performance issues with your machine when running the tool.
For stochastic datasets, it is recommended that you run 10,000 simulations, however for IBTrACS Historical data, 2,000 should be enough to get reliable output as each simulation introduces more variation on account of it really representing 20+ years of historical data. Note that for certain perils or remote types of events, even 10,000 simulations may not be enough to ensure reliable outputs. A loading bar will appear during the simulation run and a notification will display once the results are ready to view. Note that this tab may take anywhere between 20 seconds and 10 minutes to run. This will heavily depend on:
Whether you have selected stochastic hazard data or IBTrACS historical hazard data. Historical data should generally be slower to run as it effectively creates the event set during the simulation process.
The number of simulations you choose.
The size of the area selected in the exposure tab. Larger areas will take longer to run as each individual simulation will contain more events.
The region you have selected in the hazard section. Some areas are more active or contain more years of data than others.
The location of your exposure. More high hazard areas will take longer to run because a loss must be calculated on a greater number of events.
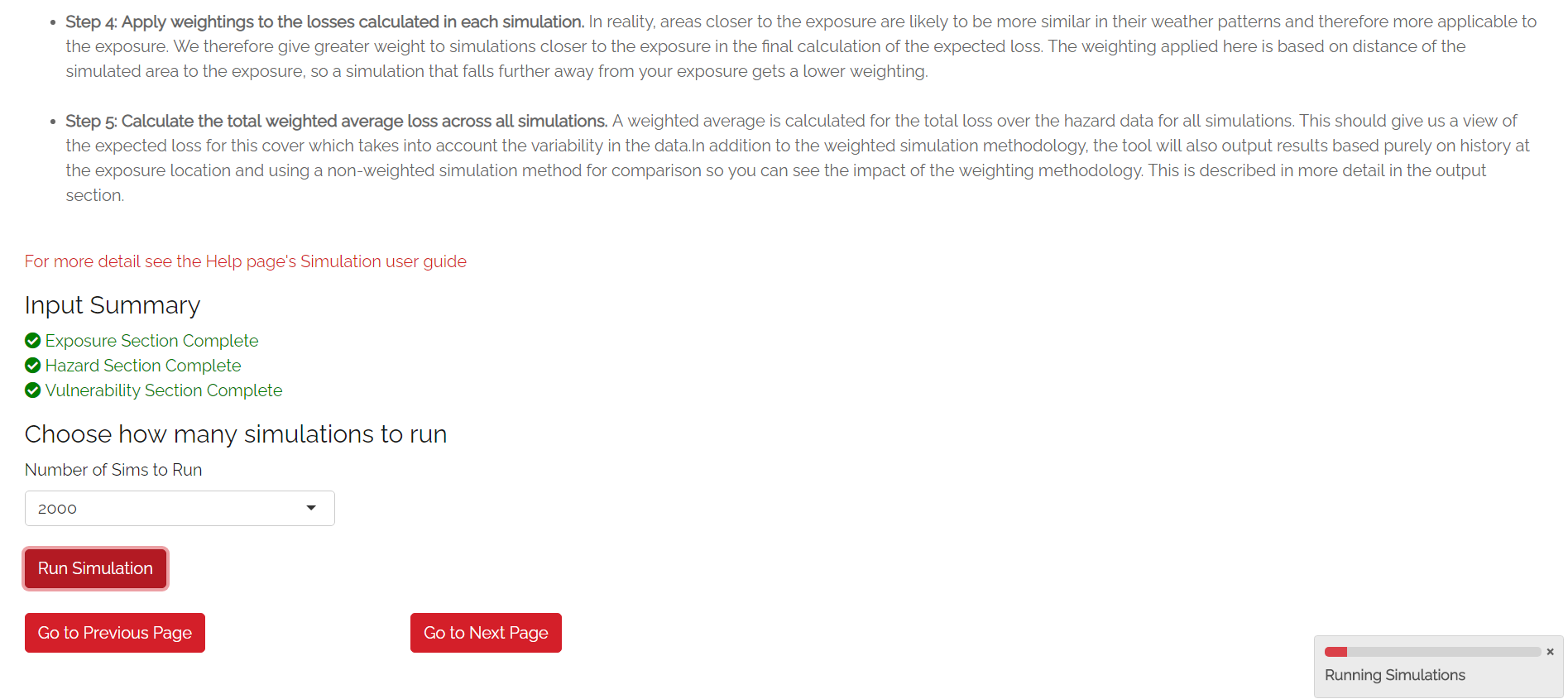
Simulation Tab
5. Event Analysis
What does it do? The event analysis tab is where detailed exhibits summarising the events in the simulation modelling can be viewed. These tables and maps aim to give the user a clear summary of the types of events generated by the model, how severe they are, and how likely they are to occur. This section also aims to give more context on what a simulation is and what the method is doing in the background. Each exhibit attempts to address different learning outcomes:
Exhibit 1: Historical Loss Summary Leaving aside simulations, what actually happened over the history at my location and what losses would I have sustained over the years?
Exhibit 2: Individual Simulation Summary What does an individual simulation actually look like? How does each simulation vary?
Exhibit 3: Event Frequency and Return Periods How often do different types of event occur?
These are all covered in more detail below. There are also further exhibits more focused on the losses generated by the model on the Loss Analysis tab. Note that output will only display on this page once simulations have been run.
User Instructions
Exhibit 1: Historical Loss Summary
This exhibit is only relevant where historical hazard data is being used, as the earthquake modelling portion of the Risk Explorer is purely based on vendor stochastic sets, this exhibit is left blank.
Exhibit 2: Individual Simulation Summary
Exhibit 2 allows you to look at the results of any individual simulation by selecting the relevant simulation number in the input box. The table immediately below gives a summary of the main outputs of the simulation. The map and corresponding table display the events in the event set that would have led to losses in each individual simulation. The main purpose of this exhibit is to give more transparency on the simulation method and how we arrive at the simulated loss figures in the Loss Analysis tab. The figures displayed here for each simulation should match what is in the exportable csv files on the Loss Summary tab.
In some cases, you may find that you have very few years with any losses at all. This means the exhibit might not be very informative for the majority of individual simulations. To get around this, it may be worth going to the “Loss Analysis” tab and downloading the csv file with individual simulation results in. This way you will know which simulations actually contain losses and can focus on those. Note that if you enter an invalid number (e.g., a decimal figure or a number larger than the total amount of simulations), nothing will display in this exhibit.
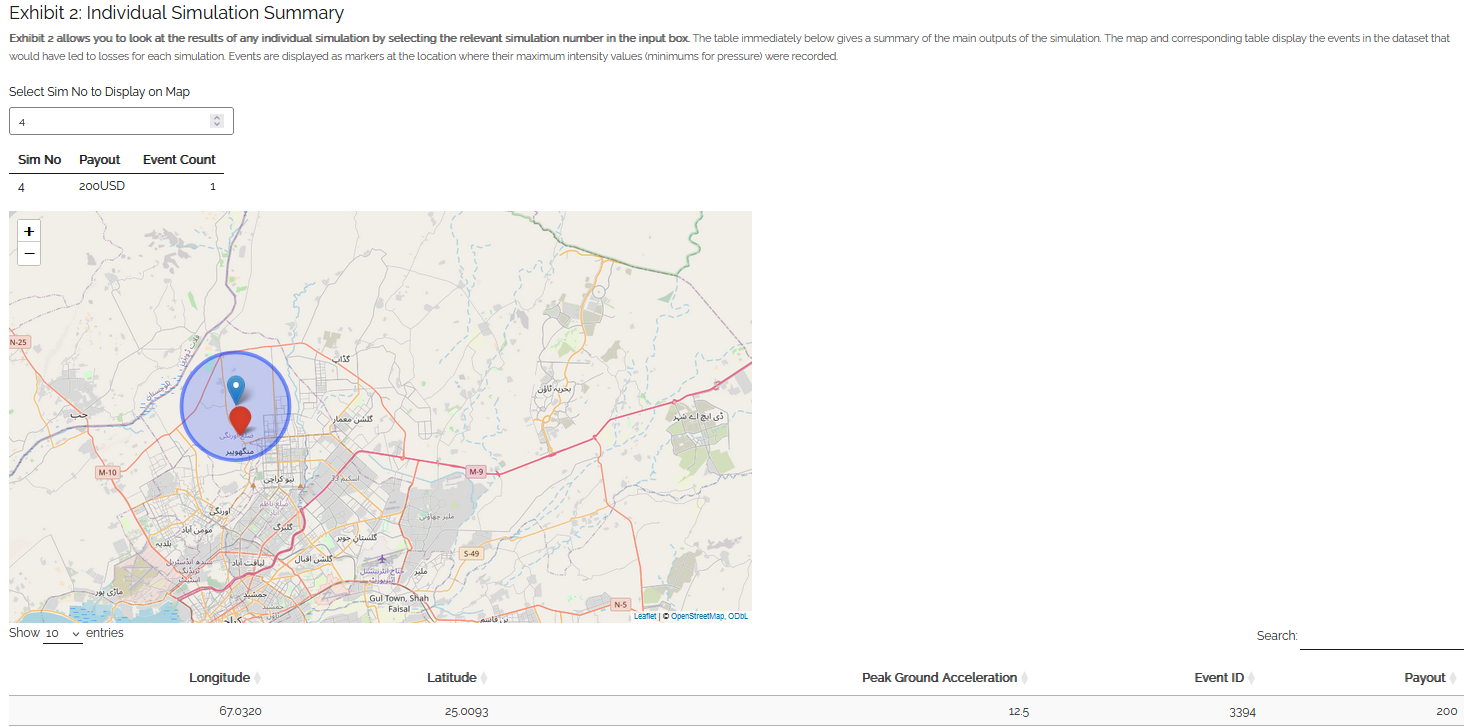
Event Analysis Tab: Exhibit 2
Exhibit 3: Event Frequency and Return Periods
Exhibit 3 gives an estimate of how often earthquakes of each MMI intensity occur in the history and in the simulation output:
Frequency refers to the number of events of this band or above you would expect to see in a year. A frequency of 1 means that an event would occur on average once a year.
Return Period refers to the average time you would have to wait before observing an event of that band or above, e.g a return period of 5 years for a cat 2 storm means you would expect to have one storm at cat 2 or above every 5 years on average. Bear in mind these represent averages, and it is possible to have two 100-year events occur in subsequent years. Another way to think about return periods is the probability of occurrence in any given year. A 10-year return period means there is a 1 in 10 (10%) chance of an event happening in any given year. Note that you will see three separate estimates of return periods by category when using IBTrACS hazard data as there are several calculation methods. By contrast for stochastic hazard datasets, you should only see one set of return periods/frequencies for the simulated loss.
This section should be useful for getting an idea of how common earthquakes of each category are around your area of exposure. Note that the relevant value denotes where each band “starts” so represents a minimum for pga.

Event Analysis Tab: Exhibit 3
**In some cases you may see NA displayed here. This means there are no earthquakes of this magnitude in the stochastic event.
6. Loss Analysis
This tab analyses the financial loss and damage generated in your modelling. The Loss Analysis tab will show you the financial loss you would expect to see on average for your risk under different calculation methods. It will also show you the full range of simulation losses and other metrics that will help you better understand the risk. This tab also allows you to export modelling results into Microsoft Excel should you wish to do further analysis. There are three main outputs on this tab:
Exhibit 4: Loss Frequency Summary How often should I expect to sustain different annual loss amounts in any given year?
Exhibit 5:Expected Loss and Distribution by Calculation Method What is my expected loss in any given year and how does this vary across simulations? This exhibit shows the distribution of different loss amounts across each simulation as well as the expected loss for each calculation method.
Raw Model Output: These are downloadable csv files containing the model output at different levels of granularity. These can be used to perform supplementary analysis or just to gain a better idea of the calculations underpinning the model. These files would also be a useful aid when reviewing the Tropical Cyclone - How does the Simulation Methodology Work? page in the FAQs.
User Instructions
Display
Note that output will only display on this page once simulations have been run. The “Display Options” section at the top of the page gives you the choice of displaying loss metrics as actual currency amounts or as a percentage of asset value, which is frequently used in insurance markets. Looking at percentage of asset value enables you to easily compare the expected losses between assets regardless of the financial amount. In some cases, it can also be a useful guide to the expected frequency of losses. E.g., consider an asset worth USD 100,000 which can only sustain 0 or 100% damage. After running a large number of simulated years, the simulated average yearly loss is calculated to be 20,000 which is 20% of the asset value. This 20% gives us an idea of the annual frequency of events hitting the asset, i.e. we would expect a loss roughly every 1 in 5 years (as it has a 20% chance of occurring in any given year). A separate asset with the same vulnerability curve and a value of USD 1,000,000 also has a simulated loss of 20,000 representing 2% of the value. We can see from the small percentage that this asset has a relatively low frequency as we would only expect it to sustain a loss every 1 in 50 years. These covers are evidently quite different despite having the same expected loss of 20,000 as one is hit far more often than the other and generally sustains more losses relative to its asset value. Although this example may appear simplistic (i.e. it would seem unlikely to have an asset that only sustained 100% damage), for a number of insurance covers 100% losses may be quite common so this way of thinking can provide some useful guide as to the likely frequency. With multiple points on our vulnerability curve we have to be a little more careful generalising, as there are losses at levels other than 100%. Nevertheless, this rule of thumb should still give a good idea of how likely the cover is to pay out in most cases.

Loss Analysis Tab: Display
Exhibit 4: Loss Frequency Summary
Exhibit 4 shows the unweighted frequency of different annual loss values or ranges in the simulation output. This exhibit should enable you to get an idea of the chances of seeing different loss values in any given year (e.g., if the red bar shows 90% for a loss of zero, then 90% of all simulation-years led to a total loss of zero). The exhibit displays individual loss values where a step vulnerability function has been entered, and loss ranges where a linear function has been used. Where ranges are displayed, these include the higher amount and exclude the lower amount e.g., USD 0-20,000 would exclude losses of zero but include losses of USD 20,000 The table below provides some more context, showing the average simulation weight for IBTrACS hazard data for each loss. The table also displays the percentile and the total count of simulation-years. Losses shown here are cumulative throughout the year and capped at the total asset value. E.g., if you had a 60% loss and a further 80% loss in a given year, this would appear as 100% in the chart.
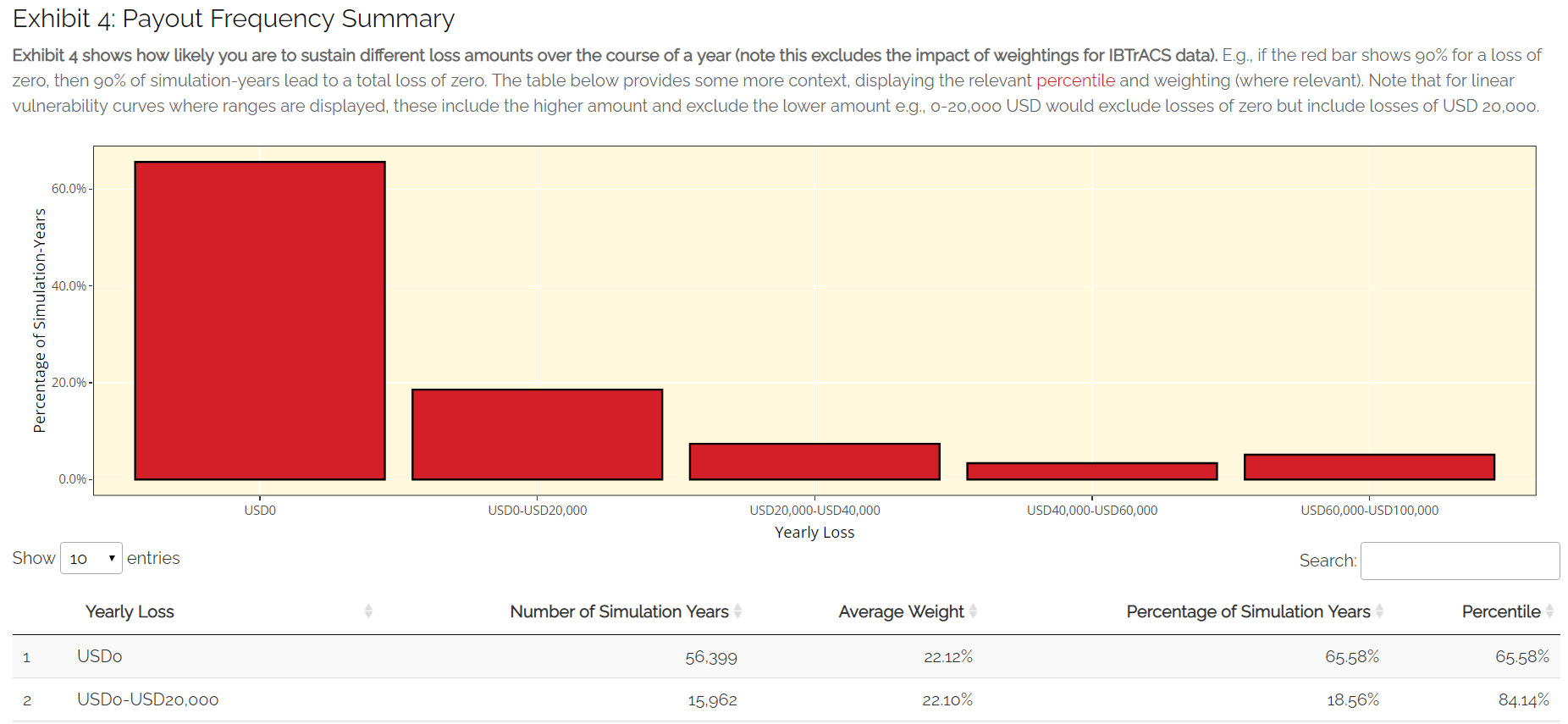
Loss Analysis Tab: Exhibit 4
Expected Loss and Distribution by Calculation Method
This exhibit shows estimates of the expected loss under different calculation methods as well as the full distribution of the simulation output. The distribution shown on the graph by the solid red line orders the simulations from the highest to lowest loss, so you can see the range of outcomes you might expect across the simulated history. The x-axis gives the loss rank of the simulation in the overall output (e.g. rank 300 of 500 simulations is the simulation that generated the 300th highest average loss). The expected loss using different methods is also displayed by horizontal lines on the graph. The bullets below describe what each method means and how it works.
Simulation Loss: This is the only method of calculating the expected loss when using stochastic hazard sets. It simply represents the average annual loss across all simulations. In principle it is very similar to the unweighted or weighted simulation loss under IBTrACS, the only difference is it is purely for the exposure rather than being sampled from other locations, thus negating the need to apply any weightings.
The table also shows the standard deviations which give an estimate of the variability of the loss. The higher the standard deviation, the more variability there is in losses across simulations. This variability is often equated with uncertainty and is one of the additional factors considered when structuring and pricing insurance contracts.
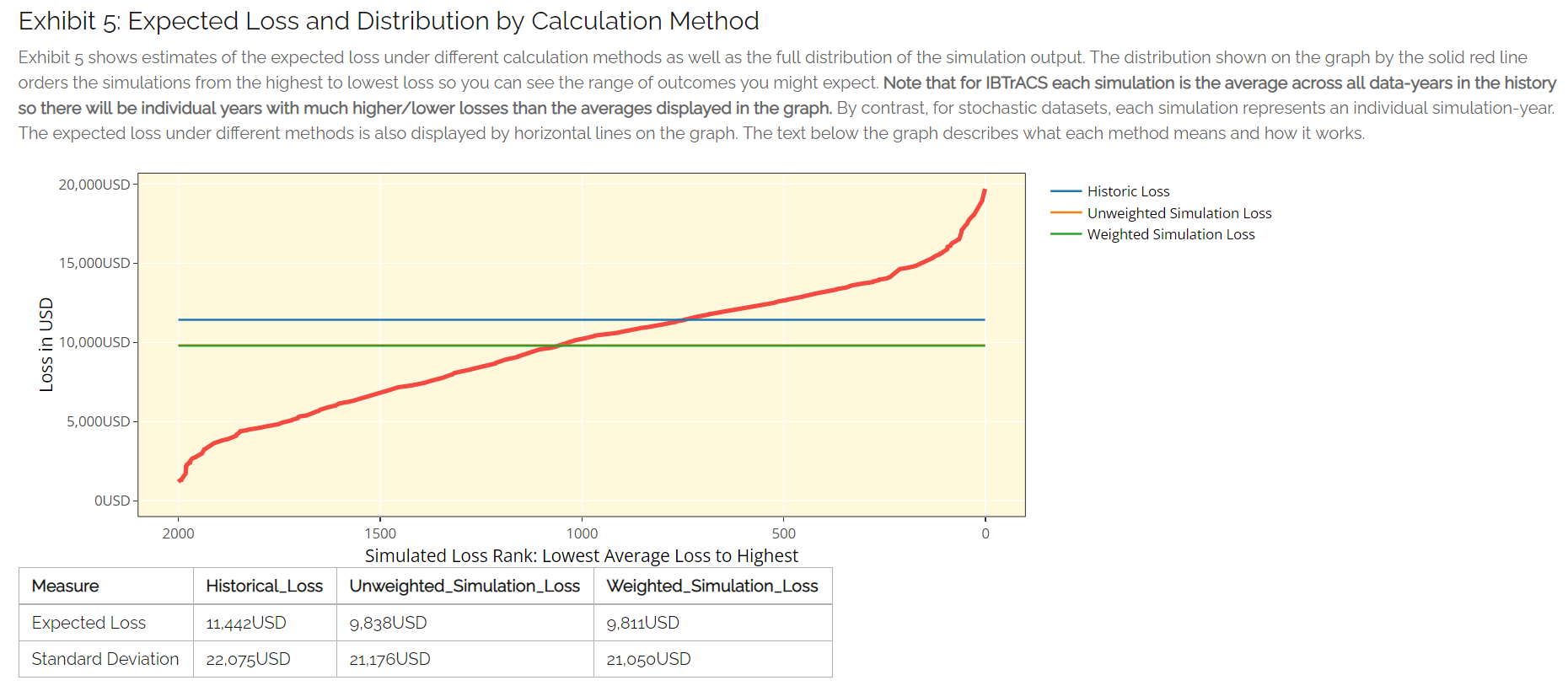
Loss Analysis Tab: Exhibit 5
Export Results to Excel
Raw model outputs can be downloaded as CSVs, two are available for IBTrACS hazard data and one for stochastic hazard data. This is due to the fact that each simulation is an individual year for stochastic data so only one file is needed for the output. By contrast for IBTrACS historical data, each simulation represents a number of years at one location. As such there are two files available here, one by simulation(location) and another by simulation-year.
Download output for each simulation: Each row in this file represents an individual year in the simulated set. The variables displayed in the file are as follows:
Unmarked first column: Row identifier
Sim No: Simulation number. Each value represents a simulated year
Payout: Simulated total payout for the year
Event count: The number of simulated events in a given simulation
Output by Simulation/Data Year Each row in this file represents an individual event in the simulated set that generated a loss/payout. The variables displayed in the file are as follows:
Unmarked first column: Row identifier
Longitude: Simulated longitude for the event in question
Latitude: Simulated latitude for the event in question
Peak Ground Acceleration: Intensity measure reading for earthquake, denoted in terms of the earth’s standard acceleration due to gravity (denoted %g)
Event ID: Code denoting a particular simulated event from the vendor’s stochastic catalog
Sim No: Simulation number. Each value represents a simulated year
Payout: The payout from the relevant event
Note that any losses will always be displayed in terms of percentage of asset value. To convert these to financial amounts in spreadsheet software, multiply them by the asset value.

Loss Analysis Tab: Export Results